Microarchitectuur (µarch): opbouw, functies en ontwerpoverwegingen
Microarchitectuur beschrijft hoe een processor intern is opgebouwd — van datapaden en pipelines tot cache en besturing — en hoe ontwerpkeuzes prestaties, energieverbruik en veiligheid beïnvloeden.
In de context van computertechniek verwijst de term microarchitectuur naar de detaillering van het elektrische of logische circuit dat een computer, een centrale verwerkingseenheid of een digitale signaalprocessor realiseert. Het begrip beschrijft de interne structuur en organisatie van de hardware (hardware) op een niveau waarop functionele blokken, datapaden en besturing zichtbaar en analyseerbaar zijn.
Afbeeldingengalerij
1 Afbeelding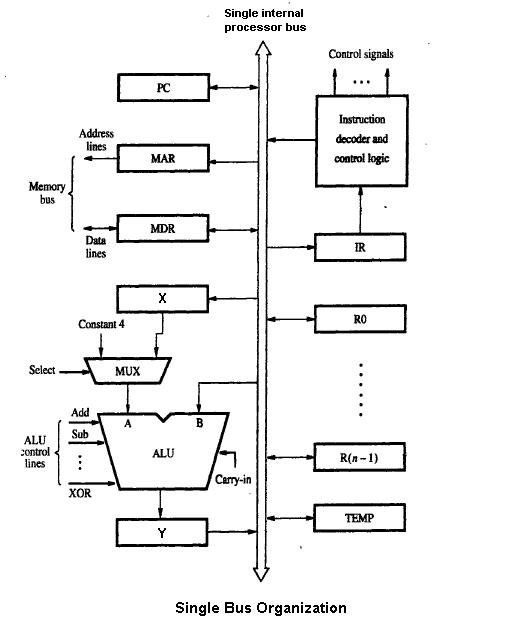
Wat een microarchitectuur omvat
Een typische microarchitectuur bevat meerdere samenwerkende onderdelen. Belangrijke onderdelen zijn:
- het datapad en de ALU (reken- en logische eenheid),
- registerbestanden en geheugeninterfaces,
- de control logic of microcode, die instructies omzet in hardwareactiviteiten,
- pipeline-stadia en scheduler voor instructie-executie,
- caches, TLB's en bus- of interconnect-ontwerpen,
- branch predictors en andere performance-enhancing middelen.
Ontwerpers combineren deze elementen om doelstellingen zoals doorvoer, latentie, energie-efficiëntie en silicon-oppervlakte te optimaliseren. Sommige systemen gebruiken vaste (hardwired) besturing, andere een laag microcode voor complexere instruction handling.
Relatie tot ISA en terminologie
Wetenschappers spreken vaak van "computerorganisatie", terwijl de industrie de term microarchitectuur gebruikt; beiden behandelen echter overlappende lagen. De microarchitectuur implementeert een hogere-level instructieset-architectuur (ISA), en samen vormen zij het vakgebied van de computerarchitectuur. Historisch zijn er verschillende stromingen — zoals CISC met microcode en RISC met eenvoudiger zwarte-box-ISA's — die ontwerpkeuzes beïnvloedden (geleerden en ingenieurs gebruiken andere termen afhankelijk van focus).
Bij de ontwikkeling worden abstractieniveaus gehanteerd: van register-transfer level (RTL) beschrijvingen tot logische poorten en uiteindelijk transistor-implementaties. Validatie gebeurt met modellering en simulatie en later met hardware-prototypen.
Microarchitectuur bepaalt in sterke mate de praktische prestaties en efficiëntie van een processor en heeft invloed op betrouwbaarheid en beveiliging — bijvoorbeeld door speculatieve uitvoering of gedeelde resources. Ontwerpkeuzes zijn altijd een afweging tussen prestaties, energieverbruik, complexiteit en kostprijs.
Voor verdere verdieping en technische voorbeelden zie bronnen over architectuurprincipes en implementatietechnieken via basisliteratuur of gespecialiseerde artikelen en handleidingen (uitleg µarch, circuitniveau, computersystemen, CPU-ontwerp, DSP-architecturen, hardwareconcepten, academische terminologie, ISA-overzicht, computerarchitectuur).
Oorsprong van de term
Computers maken sinds de jaren 1950 gebruik van microprogrammering van besturingslogica. De CPU decodeert de instructies en stuurt signalen via transistorschakelaars naar de juiste paden. De bits in de microprogrammawoorden besturen de processor op het niveau van elektrische signalen.
De term: microarchitectuur werd gebruikt om de eenheden te beschrijven die werden bestuurd door de microprogrammawoorden, in tegenstelling tot de term: "architectuur" die zichtbaar en gedocumenteerd was voor programmeurs. Terwijl de architectuur gewoonlijk compatibel moest zijn tussen verschillende hardwaregeneraties, kon de onderliggende microarchitectuur gemakkelijk worden gewijzigd.
Relatie tot instructieset architectuur
De microarchitectuur is verwant aan, maar niet hetzelfde als de instructiesetarchitectuur. De instructieset-architectuur staat dicht bij het programmeermodel van een processor zoals gezien door een programmeur van assembleertaal of een schrijver van een compiler, dat het uitvoeringsmodel, de processorregisters, de geheugenadresmodi, de adres- en gegevensformaten, enz. omvat. De microarchitectuur (of computerorganisatie) is voornamelijk een structuur op een lager niveau en beheert daarom een groot aantal details die verborgen zijn in het programmeringsmodel. Het beschrijft de interne onderdelen van de processor en hoe zij samenwerken om de architecturale specificatie uit te voeren.
Microarchitectonische elementen kunnen alles zijn, van afzonderlijke logische poorten, tot registers, opzoektabellen, multiplexers, tellers, enz. tot volledige ALU's, FPU's en zelfs grotere elementen. Het elektronische circuitniveau kan op zijn beurt worden onderverdeeld in details op transistorniveau, zoals welke basis gate-bouwstructuren worden gebruikt en welke typen logische implementatie (statisch/dynamisch, aantal fasen, enz.) worden gekozen, naast het eigenlijke logische ontwerp dat wordt gebruikt om ze te bouwen.
Enkele belangrijke punten:
- Een enkele microarchitectuur, vooral als deze microcode bevat, kan worden gebruikt om veel verschillende instructiesets te implementeren, door middel van het veranderen van de besturingsopslag. Dit kan echter behoorlijk ingewikkeld zijn, zelfs als het wordt vereenvoudigd door microcode en/of tabelstructuren in ROM's of PLA's.
- Twee machines kunnen dezelfde microarchitectuur hebben, en dus hetzelfde blokschema, maar totaal verschillende hardware-implementaties. Dit beheerst zowel het niveau van de elektronische schakelingen als nog meer het fysieke niveau van de fabricage (van zowel IC's als discrete componenten).
- Machines met verschillende microarchitecturen kunnen dezelfde instructieset-architectuur hebben, en zijn dus beide in staat om dezelfde programma's uit te voeren. Nieuwe microarchitecturen en/of circuitoplossingen, samen met vooruitgang in de halfgeleiderproductie, zorgen ervoor dat nieuwere generaties processoren hogere prestaties kunnen bereiken.
Vereenvoudigde beschrijvingen
Een zeer vereenvoudigde beschrijving op hoog niveau - gebruikelijk bij marketing - kan alleen vrij elementaire kenmerken tonen, zoals busbreedtes, samen met verschillende soorten uitvoeringseenheden en andere grote systemen, zoals vertakkingsvoorspelling en cachegeheugens, afgebeeld als eenvoudige blokken - misschien met enkele belangrijke kenmerken of eigenschappen genoteerd. Enkele details betreffende de pijplijnstructuur (zoals ophalen, decoderen, toewijzen, uitvoeren, terugschrijven) kunnen soms ook worden opgenomen.
Aspecten van de microarchitectuur
Het gepipelde datapad is het meest gebruikte datapadontwerp in de huidige microarchitectuur. Deze techniek wordt in de meeste moderne microprocessoren, microcontrollers en DSP's gebruikt. De pijplijnarchitectuur zorgt ervoor dat meerdere instructies elkaar overlappen bij de uitvoering, zoals bij een lopende band. De pijplijn omvat verschillende stadia die van fundamenteel belang zijn in microarchitectuurontwerpen. Enkele van deze stappen zijn instructie ophalen, instructie decoderen, uitvoeren en terugschrijven. Sommige architecturen omvatten ook andere stadia, zoals geheugentoegang. Het ontwerp van pijplijnen is een van de centrale taken van de microarchitectuur.
Uitvoeringseenheden zijn ook essentieel voor de microarchitectuur. Executie-eenheden omvatten rekenkundige logische eenheden (ALU), floating point units (FPU), load/store-eenheden en branch prediction. Deze eenheden voeren de bewerkingen of berekeningen van de processor uit. De keuze van het aantal uitvoeringseenheden, hun latentie en verwerkingscapaciteit zijn belangrijke taken voor het microarchitectuurontwerp. De grootte, latentie, verwerkingscapaciteit en connectiviteit van de geheugens binnen het systeem zijn ook microarchitecturele beslissingen.
Ontwerpbeslissingen op systeemniveau, zoals het al dan niet opnemen van randapparatuur, zoals geheugencontrollers, kunnen worden beschouwd als onderdeel van het microarchitectuurontwerp. Dit omvat beslissingen over het prestatieniveau en de connectiviteit van deze randapparatuur.
In tegenstelling tot architectuurontwerp, waarbij een specifiek prestatieniveau het hoofddoel is, wordt bij microarchitectuurontwerp meer aandacht besteed aan andere beperkingen. Er moet aandacht worden besteed aan zaken als:
- Chipgebied/kosten.
- Stroomverbruik.
- Logische complexiteit.
- Verbindingsgemak.
- Fabriceerbaarheid.
- Gemakkelijk debuggen.
- Testbaarheid.
Micro-architecturele concepten
In het algemeen voeren alle CPU's, single-chip microprocessoren of multi-chip implementaties, programma's uit door de volgende stappen uit te voeren:
- Een instructie lezen en decoderen.
- Zoek alle bijbehorende gegevens die nodig zijn om de instructie te verwerken.
- Verwerk de instructie.
- Schrijf de resultaten uit.
Deze eenvoudig ogende reeks stappen wordt gecompliceerd door het feit dat de geheugenhiërarchie, die caching, hoofdgeheugen en niet-vluchtige opslag zoals harde schijven omvat (waar de programma-instructies en gegevens zich bevinden), altijd trager is geweest dan de processor zelf. Stap (2) introduceert vaak een vertraging (in CPU-termen vaak een "stall" genoemd) terwijl de gegevens over de computerbus aankomen. Er is veel onderzoek gedaan naar ontwerpen die deze vertragingen zoveel mogelijk voorkomen. In de loop der jaren was een centraal ontwerpdoel het parallel uitvoeren van meer instructies, waardoor de effectieve uitvoeringssnelheid van een programma werd verhoogd. Bij deze inspanningen werden ingewikkelde logica- en circuitstructuren ingevoerd. In het verleden konden dergelijke technieken alleen worden toegepast op dure mainframes of supercomputers vanwege de hoeveelheid schakelingen die voor deze technieken nodig waren. Naarmate de fabricage van halfgeleiders vorderde, konden steeds meer van deze technieken op een enkele halfgeleiderchip worden geïmplementeerd.
Wat volgt is een overzicht van microarchitectuurtechnieken die gangbaar zijn in moderne CPU's.
Keuze van de instructieset
De keuze van de te gebruiken Instructieset-architectuur is van grote invloed op de complexiteit van de implementatie van krachtige apparaten. In de loop der jaren hebben computerontwerpers hun best gedaan om instructiesets te vereenvoudigen, teneinde implementaties met hogere prestaties mogelijk te maken door ontwerpers moeite en tijd te besparen voor functies die de prestaties verbeteren in plaats van deze te verspillen aan de complexiteit van de instructieset.
Het ontwerp van instructiesets is geëvolueerd van CISC, RISC, VLIW en EPIC types. Architecturen die zich bezighouden met dataparallellisme omvatten SIMD en vectoren.
Instructie pipelining
Een van de eerste, en krachtigste, technieken om de prestaties te verbeteren is het gebruik van de instructiepijplijn. Vroege processorontwerpen voerden alle bovenstaande stappen uit op één instructie voordat ze naar de volgende gingen. Grote delen van het processorcircuit werden bij elke stap inactief gelaten; zo was het instructiedecoderingscircuit inactief tijdens de uitvoering, enzovoort.
Pipelines verbeteren de prestaties door een aantal instructies tegelijkertijd door de processor te laten lopen. In hetzelfde basisvoorbeeld zou de processor beginnen met het decoderen (stap 1) van een nieuwe instructie terwijl de laatste instructie wacht op resultaat. Hierdoor kunnen er tot vier instructies tegelijk "in de lucht" zijn, waardoor de processor vier keer zo snel lijkt. Hoewel elke instructie even lang duurt (er zijn nog steeds vier stappen), is de CPU als geheel veel sneller klaar en kan hij met een veel hogere kloksnelheid werken.
Cache
Dankzij verbeteringen in de chipfabricage konden meer schakelingen op dezelfde chip worden geplaatst, en ontwerpers gingen op zoek naar manieren om die te gebruiken. Een van de meest gebruikelijke manieren was het toevoegen van een steeds grotere hoeveelheid cachegeheugen op de chip. Cache is een zeer snel geheugen, geheugen dat in enkele cycli kan worden aangesproken in vergelijking met wat nodig is om met het hoofdgeheugen te praten. De CPU bevat een cache-controller die het lezen en schrijven uit de cache automatiseert; als de gegevens al in de cache zitten, "verschijnt" ze gewoon, terwijl als dat niet het geval is, de processor "stilvalt" terwijl de cache-controller ze inleest.
RISC-ontwerpen begonnen midden tot eind jaren tachtig cache toe te voegen, vaak slechts 4 KB in totaal. Dit aantal groeide in de loop der tijd, en typische CPU's hebben nu ongeveer 512 KB, terwijl krachtigere CPU's worden geleverd met 1 of 2 of zelfs 4, 6, 8 of 12 MB, georganiseerd in meerdere niveaus van een geheugenhiërarchie. Over het algemeen betekent meer cache meer snelheid.
Caches en pijplijnen pasten perfect bij elkaar. Vroeger had het niet veel zin om een pijplijn te bouwen die sneller kon lopen dan de toegangslatentie van het off-chip cachegeheugen. Door in plaats daarvan on-chip cachegeheugen te gebruiken, kon een pijplijn lopen op de snelheid van de toegangslatentie van de cache, een veel kortere tijd. Hierdoor konden de bedrijfsfrequenties van processoren veel sneller toenemen dan die van het off-chip geheugen.
Takvoorspelling en speculatieve uitvoering
Pipeline stalls en flushes als gevolg van vertakkingen zijn de twee belangrijkste zaken die het bereiken van hogere prestaties door parallellisme op instructieniveau in de weg staan. Vanaf het moment dat de instructiedecoder van de processor heeft vastgesteld dat hij een voorwaardelijke vertakkingsinstructie is tegengekomen tot het moment dat de beslissende sprongregisterwaarde kan worden uitgelezen, kan de pijplijn verscheidene cycli stilstaan. Gemiddeld is elke vijfde uitgevoerde instructie een vertakking, dus dat is een groot aantal vertragingen. Als de vertakking wordt genomen, is het nog erger, want dan moeten alle volgende instructies die in de pijplijn zaten, worden doorgespoeld.
Technieken zoals vertakkingsvoorspelling en speculatieve uitvoering worden gebruikt om deze vertakkingskosten te verminderen. Bij vertakkingsvoorspelling maakt de hardware een beredeneerde gok of een bepaalde vertakking zal worden genomen. Deze gok stelt de hardware in staat instructies te pre-fetchen zonder te wachten op het lezen van het register. Speculatieve uitvoering is een verdere verbetering waarbij de code langs het voorspelde pad wordt uitgevoerd voordat bekend is of de vertakking al dan niet moet worden genomen.
Uitvoering buiten de orde
De toevoeging van caches vermindert de frequentie of duur van stalls door het wachten op gegevens uit de hoofdgeheugenhiërarchie, maar maakt geen einde aan deze stalls. In vroege ontwerpen dwong een cache-miss de cache-controller de processor te stoppen en te wachten. Natuurlijk kan er een andere instructie in het programma zijn waarvan de gegevens op dat moment beschikbaar zijn in de cache. Out-of-order uitvoering laat die klaarstaande instructie verwerken terwijl een oudere instructie in de cache wacht, en herschikt de resultaten zodat het lijkt alsof alles in de geprogrammeerde volgorde is gebeurd.
Superscalair
Zelfs met alle extra complexiteit en poorten die nodig waren om de hierboven beschreven concepten te ondersteunen, maakten verbeteringen in de halfgeleiderfabricage het al snel mogelijk om nog meer logische poorten te gebruiken.
In het bovenstaande schema verwerkt de processor delen van één instructie tegelijk. Computerprogramma's zouden sneller kunnen worden uitgevoerd als meerdere instructies tegelijkertijd werden verwerkt. Dit is wat superscalaire processoren bereiken, door functionele eenheden zoals ALU's te repliceren. De replicatie van functionele eenheden werd pas mogelijk toen het oppervlak van de geïntegreerde schakelingen (soms "dobbelsteen" genoemd) van een processor met één opdracht niet langer de grenzen opzocht van wat betrouwbaar kon worden geproduceerd. Eind jaren tachtig begonnen superscalaire ontwerpen hun intrede te doen op de markt.
In moderne ontwerpen is het gebruikelijk dat er twee laadeenheden zijn, één opslag (veel instructies hebben geen resultaten om op te slaan), twee of meer integer rekeneenheden, twee of meer floating point eenheden, en vaak een of andere SIMD-eenheid. De instructies worden steeds ingewikkelder door een enorme lijst instructies uit het geheugen in te lezen en door te geven aan de verschillende uitvoeringseenheden die op dat moment inactief zijn. De resultaten worden vervolgens verzameld en aan het eind opnieuw geordend.
Hernoemen van registers
Het hernoemen van registers verwijst naar een techniek die wordt gebruikt om onnodige seriële uitvoering van programma-instructies te voorkomen vanwege het hergebruik van dezelfde registers door die instructies. Stel dat wij twee groepen instructies hebben die hetzelfde register zullen gebruiken, dan wordt één set instructies eerst uitgevoerd om het register over te laten aan de andere set, maar als de andere set is toegewezen aan een ander soortgelijk register kunnen beide sets instructies parallel worden uitgevoerd.
Multiprocessing en multithreading
Door het groeiende verschil tussen de werkingsfrequenties van CPU's en de toegangstijden tot DRAM kon geen van de technieken die het instructieniveau binnen één programma verbeteren, de lange stalls (vertragingen) overwinnen die optraden wanneer gegevens uit het hoofdgeheugen moesten worden opgehaald. Bovendien vereisten de grote transistoraantallen en de hoge werkfrequenties die nodig zijn voor de meer geavanceerde ILP-technieken een vermogensverlies dat niet langer goedkoop gekoeld kon worden. Om deze redenen zijn nieuwere generaties computers gebruik gaan maken van hogere niveaus van parallellisme buiten een enkel programma of een enkele thread.
Deze trend wordt ook wel "throughput computing" genoemd. Dit idee vindt zijn oorsprong in de mainframemarkt, waar bij online transactieverwerking niet alleen de nadruk werd gelegd op de uitvoeringssnelheid van één transactie, maar ook op de capaciteit om grote aantallen transacties tegelijk te verwerken. Nu op transacties gebaseerde toepassingen zoals netwerkrouting en webservices de laatste tien jaar sterk zijn toegenomen, heeft de computerindustrie opnieuw de nadruk gelegd op capaciteit en doorvoer.
Eén techniek om dit parallellisme te bereiken is via multiprocessorsystemen, computersystemen met meerdere processoren. In het verleden was dit voorbehouden aan high-end mainframes, maar nu zijn kleinschalige (2-8) multiprocessorservers gemeengoed geworden voor de kleine bedrijvenmarkt. Voor grote bedrijven zijn grootschalige (16-256) multiprocessors gebruikelijk. Zelfs personal computers met meerdere CPU's verschijnen sinds de jaren negentig.
Door de vooruitgang in de halfgeleidertechnologie is de transistorgrootte afgenomen; er zijn multicore CPU's verschenen waarbij meerdere CPU's op dezelfde siliciumchip worden geïmplementeerd. Aanvankelijk werden ze gebruikt in chips voor ingebedde markten, waar met eenvoudigere en kleinere CPU's meerdere instantiaties op één stuk silicium passen. Tegen 2005 maakte de halfgeleidertechnologie het mogelijk om dual high-end desktop CPU's CMP-chips in volume te produceren. Sommige ontwerpen, zoals UltraSPARC T1, gebruikten een eenvoudiger (scalair, in-order) ontwerp om meer processoren op één stuk silicium te passen.
Een andere techniek die de laatste tijd populairder is geworden, is multithreading. Bij multithreading, wanneer de processor gegevens moet ophalen uit een traag systeemgeheugen, schakelt de processor, in plaats van te wachten tot de gegevens aankomen, over naar een ander programma of een andere thread die klaar is om te worden uitgevoerd. Hoewel dit een bepaald programma/thread niet versnelt, verhoogt het de totale systeemdoorvoer doordat de CPU minder lang inactief is.
Conceptueel gezien is multithreading gelijk aan een contextswitch op het niveau van het besturingssysteem. Het verschil is dat een multithreaded CPU een thread-switch kan uitvoeren in één CPU-cyclus in plaats van de honderden of duizenden CPU-cycli die een context-switch normaal vereist. Dit wordt bereikt door de toestandshardware (zoals het registerbestand en de programmateller) voor elke actieve thread te repliceren.
Een verdere verbetering is simultane multithreading. Met deze techniek kunnen superscalaire CPU's instructies van verschillende programma's/threads tegelijkertijd in dezelfde cyclus uitvoeren.
Gerelateerde pagina's
- Microprocessor
- Microcontroller
- Multi-core processor
- Digitale signaalprocessor
- CPU-ontwerp
- Datapath
- Parallellisme op instructieniveau (ILP)
Vragen en antwoorden
V: Wat is microarchitectuur?
A: Microarchitectuur is een beschrijving van het elektrische circuit van een computer, centrale verwerkingseenheid of digitale signaalprocessor die volstaat om de werking van de hardware volledig te beschrijven.
V: Hoe verwijzen wetenschappers naar dit concept?
A: Geleerden gebruiken de term "computerorganisatie" wanneer zij verwijzen naar microarchitectuur.
V: Hoe verwijzen mensen in de computerindustrie naar dit concept?
A: Mensen in de computerindustrie zeggen vaker "microarchitectuur" wanneer zij naar dit concept verwijzen.
V: Uit welke twee gebieden bestaat de computerarchitectuur?
A: Microarchitectuur en instructieset architectuur (ISA) vormen samen het gebied van de computerarchitectuur.
V: Waar staat ISA voor?
A: ISA staat voor Instruction Set Architecture.
V: Waar staat µarch voor? A: µArch staat voor Microarchitectuur.
Gerelateerde artikelen
Auteur
AlegsaOnline.com Microarchitectuur (µarch): opbouw, functies en ontwerpoverwegingen Leandro Alegsa
URL: https://nl.alegsaonline.com/art/64586
Bronnen
- computer.org : IEEE Computer Society
- extremetech.com : PC Processor Microarchitecture