Redundant array of independent disks
Inhoud · 1 Inleiding o 1.1 Verschil tussen fysieke schijven en logische schijven o 1.2 Lees- en schrijfgegevens o 1.3 Wat is RAID? o 1.4 Waarom RAID gebruiken? o 1.5 Geschiedenis · 2 Basisconcepten van RAID-systemen o 2.1 Caching o 2.2 Spiegelen…
Inhoud
· 1 Inleiding
o 1.1 Verschil tussen fysieke schijven en logische schijven
o 1.2 Lees- en schrijfgegevens
o 1.3 Wat is RAID?
o 1.4 Waarom RAID gebruiken?
o 1.5 Geschiedenis
· 2 Basisconcepten van RAID-systemen
o 2.1 Caching
o 2.2 Spiegelen: Meer dan één kopie van de gegevens
o 2.3 Striping: Een deel van de gegevens staat op een andere schijf
o 2.4 Foutcorrectie en fouten
o 2.5 Warme reserveonderdelen: meer schijven gebruiken dan nodig is
o 2.6 Streepgrootte en brokkengrootte: spreiding van de gegevens over meerdere schijven
o 2.7 Schijf in elkaar zetten: JBOD, aaneenschakeling of overspanning
o 2.8 Aandrijfkloon
o 2.9 Verschillende opstellingen
· 3 Grondbeginselen: eenvoudige RAID-niveaus
o 3.1 RAID-niveaus in gemeenschappelijk gebruik
§ 3.1.1 RAID 0 "striping"
§ 3.1.2 RAID 1 "Spiegeling".
§ 3.1.3 RAID 5 "striping met verdeelde pariteit".
§ 3.1.4 Foto's
o 3.2 RAID-niveaus minder gebruikt
§ 3.2.1 RAID 2
§ 3.2.2 RAID 3 "striping met specifieke pariteit".
§ 3.2.3 RAID 4 "striping met specifieke pariteit".
§ 3.2.4 RAID 6
§ 3.2.5 Foto's
o 3.3 Niet-standaard RAID-niveaus
§ 3.3.1 Dubbele pariteit / Diagonale pariteit
§ 3.3.2 RAID-DP
§ 3.3.3 RAID 1.5
§ 3.3.4 RAID 5E, RAID 5EE en RAID 6E
§ 3.3.5 RAID 7
§ 3.3.6 Intel Matrix RAID
§ 3.3.7 Linux MD RAID-stuurprogramma
§ 3.3.8 RAID Z
§ 3.3.9 Foto's
· 4 Aansluiting bij RAID-niveaus
· 5 Een RAID maken
o 5.1 Software RAID
o 5.2 Hardware RAID
o 5.3 Hardware-ondersteunde RAID
· 6 Verschillende termen met betrekking tot hardwarestoringen
o 6.1 Storingspercentage
o 6.2 Gemiddelde tijd tot gegevensverlies
o 6.3 Gemiddelde tijd tot herstel
o 6.4 Onherstelbare bitfoutpercentage
· 7 Problemen met RAID
o 7.1 Schijven toevoegen op een later tijdstip
o 7.2 Gekoppelde storingen
o 7.3 Atomiciteit
o 7.4 Onherstelbare gegevens
o 7.5 Betrouwbaarheid van de cache
o 7.6 Compatibiliteit van de apparatuur
· 8 Wat RAID wel en niet kan doen
o 8.1 Wat RAID kan doen
o 8.2 Wat RAID niet kan doen
· 9 Voorbeeld
· 10 Referenties
· 11 Andere websites
RAID is een acroniem dat staat voor Redundant Array of Inexpensive Disks of Redundant Array of Independent Disks. RAID is een term die gebruikt wordt in de informatica. Met RAID worden meerdere harde schijven tot één logische schijf gemaakt. Er zijn verschillende manieren om dit te doen. Elk van de methoden die de harde schijven samenvoegen heeft een aantal voordelen en nadelen ten opzichte van het gebruik van de schijven als enkelvoudige schijven, onafhankelijk van elkaar. De belangrijkste redenen waarom RAID wordt gebruikt zijn:
- Om het verlies van gegevens minder vaak te laten gebeuren. Dit wordt gedaan door meerdere kopieën van de gegevens te hebben.
- Om meer opslagruimte te krijgen door veel kleinere schijven te hebben.
- Om meer flexibiliteit te krijgen (Schijven kunnen worden veranderd of toegevoegd terwijl het systeem blijft draaien)
- Om de gegevens sneller te krijgen.
Het is niet mogelijk om al deze doelen tegelijkertijd te bereiken, dus er moeten keuzes worden gemaakt.
Er zijn ook wat slechte dingen:
- Bepaalde keuzes kunnen bescherming bieden tegen het verlies van gegevens doordat één (of een aantal) schijven faalt. Ze bieden echter geen bescherming tegen het wissen of overschrijven van de gegevens.
- In sommige configuraties kan RAID tolereren dat één of een aantal schijven faalt. Nadat de defecte schijven zijn vervangen, moeten de gegevens worden gereconstrueerd. Afhankelijk van de configuratie en de grootte van de schijven kan deze reconstructie lang duren.
- Bepaalde soorten fouten zullen het onmogelijk maken om de gegevens te lezen
Het grootste deel van het werk aan RAID is gebaseerd op een document dat in 1988 is geschreven.
Bedrijven gebruiken sinds het maken van de technologie RAID-systemen om hun gegevens op te slaan. Er zijn verschillende manieren waarop RAID-systemen kunnen worden gemaakt. Sinds de ontdekking ervan zijn de kosten voor het bouwen van een RAID-systeem sterk gedaald. Daarom hebben zelfs sommige computers en apparaten die thuis worden gebruikt een aantal RAID-functies. Dergelijke systemen kunnen bijvoorbeeld worden gebruikt om muziek of films op te slaan.
Inleiding
Verschil tussen fysieke schijven en logische schijven
Een harde schijf is een onderdeel van een computer. Normale harde schijven gebruiken magnetisme om informatie op te slaan. Wanneer harde schijven worden gebruikt, zijn ze beschikbaar voor het besturingssysteem. In Microsoft Windows krijgt elke harde schijf een stationsletter (beginnend met C:, A: of B: zijn gereserveerd voor diskettes). Unix- en Linux-achtige besturingssystemen hebben een eenduidige mappenstructuur. Dit betekent dat mensen die de computers gebruiken soms niet weten waar de informatie is opgeslagen. (Om eerlijk te zijn weten veel Windows gebruikers ook niet waar hun gegevens zijn opgeslagen).
In de computerwereld worden de harde schijven (die hardware zijn en aangeraakt kunnen worden) soms ook wel fysieke schijven genoemd. Wat het besturingssysteem aan de gebruiker laat zien, wordt soms ook wel logische schijf genoemd. Een fysieke schijf kan worden opgesplitst in verschillende secties, die schijfpartities worden genoemd. Meestal bevat elke schijfpartitie één bestandssysteem. Het besturingssysteem toont elke partitie als een logische schijf.
Daarom zal voor de gebruiker zowel de opstelling met veel fysieke schijven als de opstelling met veel logische schijven er hetzelfde uitzien. De gebruiker kan niet beslissen of een "logische schijf" hetzelfde is als een fysieke schijf, of dat het gewoon een deel van de schijf is. Storage Area Networks (SAN's) veranderen deze weergave volledig. Het enige dat zichtbaar is van een SAN is een aantal logische schijven.
Lees- en schrijfgegevens
In de computer zijn de gegevens georganiseerd in de vorm van bits en bytes. In de meeste systemen vormen 8 bits een byte. Het computergeheugen gebruikt elektriciteit om de gegevens op te slaan, harde schijven gebruiken magnetisme. Daarom wordt bij het schrijven van gegevens op een schijf het elektrische signaal omgezet in een magnetisch signaal. Wanneer de gegevens van de schijf worden gelezen, gebeurt de conversie in de andere richting: Een elektrisch signaal wordt gemaakt van de polariteit van een magnetisch veld.
Wat is RAID?
Een RAID-array verbindt twee of meer harde schijven zodat ze een logische schijf vormen. Er zijn verschillende redenen waarom dit gebeurt. De meest voorkomende zijn:
- Het stoppen van dataverlies, wanneer een of meer schijven van de array falen.
- Snellere gegevensoverdracht.
- De mogelijkheid om schijven te wisselen terwijl het systeem blijft draaien.
- Het samenvoegen van meerdere schijven om meer opslagcapaciteit te krijgen; soms worden veel goedkope schijven gebruikt, in plaats van een duurdere.
RAID wordt gedaan met behulp van speciale hardware of software op de computer. De samengevoegde harde schijven zien er dan uit als één harde schijf voor de gebruiker. De meeste RAID-niveaus verhogen de redundantie. Dit betekent dat ze de gegevens vaker opslaan, of ze slaan informatie op over hoe de gegevens te reconstrueren. Dit maakt het mogelijk dat een aantal schijven uitvalt zonder dat de gegevens verloren gaan. Wanneer de defecte schijf wordt vervangen, worden de gegevens die deze zou moeten bevatten, gekopieerd of opnieuw opgebouwd vanaf de andere schijven van het systeem. Dit kan lang duren. De tijd die hiervoor nodig is hangt af van verschillende factoren, zoals de grootte van de array.
Waarom RAID gebruiken?
Een van de redenen waarom veel bedrijven RAID gebruiken is dat de gegevens in de array gewoon gebruikt kunnen worden. Degenen die de gegevens gebruiken hoeven zich er niet van bewust te zijn dat ze RAID gebruiken. Wanneer er een storing optreedt en de array herstelt, zal de toegang tot de gegevens langzamer zijn. Toegang tot de data gedurende deze tijd zal ook het herstelproces vertragen, maar dit is nog steeds veel sneller dan het helemaal niet kunnen werken met de data. Afhankelijk van het RAID-niveau is het echter mogelijk dat schijven niet falen terwijl de nieuwe schijf wordt klaargemaakt voor gebruik. Een schijf die op dat moment faalt, zal resulteren in het verlies van alle gegevens in de array.
De verschillende manieren om schijven samen te voegen worden RAID-niveaus genoemd. Een groter aantal voor het niveau is niet noodzakelijkerwijs beter. Verschillende RAID-niveaus hebben verschillende doelen. Sommige RAID-niveaus hebben speciale schijven en speciale controllers nodig.
Geschiedenis
In 1978 deed een man genaamd Norman Ken Ouchi, die bij IBM werkte, een suggestie om de plannen te beschrijven voor wat later RAID 5 zou worden. De plannen beschreven ook iets wat lijkt op RAID 1, evenals de bescherming van een deel van RAID 4.
Werknemers van de Universiteit van Berkeley hielpen bij de planning van het onderzoek in 1987. Ze probeerden het mogelijk te maken dat de RAID-technologie twee harde schijven kon herkennen in plaats van één. Ze ontdekten dat wanneer de RAID-technologie twee harde schijven had, het veel betere opslagruimte had dan met slechts één harde schijf. Het is echter veel vaker gecrasht.
In 1988 werden de verschillende soorten RAID (1 tot 5), geschreven door David Patterson, Garth Gibson en Randy Katz in hun artikel "A Case for Redundant Arrays of Inexpensive Disks (RAID)". Dit artikel was de eerste die de nieuwe technologie RAID noemde en de naam werd officieel.


Basisconcepten gebruikt door RAID-systemen
RAID maakt gebruik van enkele basisideeën, die werden beschreven in het artikel "RAID: High-Performance, Reliable Secondary Storage" van Peter Chen en anderen, gepubliceerd in 1994.
Caching
Caching is een technologie die ook in RAID-systemen wordt toegepast. Er zijn verschillende soorten caches die in RAID-systemen worden gebruikt:
- Besturingssysteem
- RAID-controller
- Enterprise-schijfarray
In moderne systemen wordt een schrijfaanvraag getoond zoals die is gedaan wanneer de gegevens naar de cache zijn geschreven. Dit betekent niet dat de gegevens naar de schijf zijn geschreven. Verzoeken van de cache worden niet noodzakelijkerwijs in dezelfde volgorde behandeld als wanneer ze naar de cache zijn geschreven. Dit maakt het mogelijk dat, als het systeem uitvalt, sommige gegevens soms niet naar de betrokken schijf zijn geschreven. Om deze reden hebben veel systemen een cache die wordt ondersteund door een batterij.
Spiegelen: Meer dan één kopie van de gegevens
Als we het over een spiegel hebben, is dit een heel eenvoudig idee. In plaats van dat de gegevens op één plaats staan, zijn er meerdere kopieën van de gegevens. Deze kopieën staan meestal op verschillende harde schijven (of schijfpartities). Als er twee kopieën zijn, kan één ervan falen zonder dat de gegevens worden aangetast (zoals dat nog steeds het geval is op de andere kopie). Spiegelen kan ook een boost geven bij het lezen van gegevens. Het wordt altijd genomen van de snelste schijf die reageert. Het schrijven van data is echter langzamer, omdat alle schijven moeten worden geüpdatet.
Striping: Een deel van de gegevens staat op een andere schijf
Met striping worden de gegevens in verschillende delen gesplitst. Deze delen komen dan op verschillende schijven (of schijfpartities) terecht. Dit betekent dat het schrijven van data sneller gaat, omdat het parallel kan worden gedaan. Dit betekent niet dat er geen fouten zullen optreden, aangezien elk blok data slechts op één schijf te vinden is.
Foutcorrectie en fouten
Het is mogelijk om verschillende soorten controlesommen te berekenen. Sommige methoden voor het berekenen van checksums maken het mogelijk om een fout te vinden. De meeste RAID-niveaus die gebruik maken van redundantie kunnen dit doen. Sommige methoden zijn moeilijker te doen, maar ze maken het mogelijk om niet alleen de fout op te sporen, maar ook om deze te repareren.
Hete reserveonderdelen: meer schijven gebruiken dan nodig is
Veel van de manieren om RAID-ondersteuning te hebben heet een hot spare. Een hot spare is een lege schijf die niet wordt gebruikt bij normaal gebruik. Wanneer een schijf uitvalt, kunnen gegevens direct naar de hot spare schijf worden gekopieerd. Op die manier moet de defecte schijf worden vervangen door een nieuwe, lege schijf om de "hot spare" te worden.
Streepgrootte en brokmaat: spreiding van de gegevens over meerdere schijven
RAID werkt door de gegevens over meerdere schijven te verspreiden. Twee van de termen die in dit verband vaak worden gebruikt zijn streepjesmaat en brokkenmaat.
De chunkgrootte is het kleinste gegevensblok dat naar een enkele schijf van de array wordt geschreven. De streepgrootte is de grootte van een gegevensblok dat over alle schijven wordt verspreid. Op die manier wordt met vier schijven, en een streepgrootte van 64 kilobyte (kB), 16 kB naar elke schijf geschreven. De blokgrootte in dit voorbeeld is dus 16 kB. Het groter maken van de streepgrootte betekent een snellere gegevensoverdracht, maar ook een grotere maximale latentie. In dit geval is dit de tijd die nodig is om een blok data te krijgen.
Schijf in elkaar zetten: JBOD, aaneenschakeling of overspanning
Veel controllers (en ook software) kunnen op de volgende manier schijven in elkaar zetten: Neem de eerste schijf, tot het einde, dan nemen ze de tweede, enzovoort. Op die manier lijken meerdere kleinere schijven op een grotere. Dit is niet echt RAID, omdat er geen redundantie is. Ook kan spanning schijven combineren waar RAID 0 niets kan doen. Over het algemeen wordt dit slechts een aantal schijven (JBOD) genoemd.
Dit is als een verre verwant van RAID omdat de logische schijf is gemaakt van verschillende fysieke schijven. Aaneenschakeling wordt soms gebruikt om meerdere kleine schijven om te zetten in één grotere bruikbare schijf. Dit kan niet worden gedaan met RAID 0. JBOD zou bijvoorbeeld 3 GB, 15 GB, 5,5 GB en 12 GB schijven kunnen combineren tot een logische schijf met 35,5 GB, wat vaak nuttiger is dan de schijven alleen.
In het diagram hiernaast worden de gegevens samengevoegd van het einde van schijf 0 (blok A63) tot het begin van schijf 1 (blok A64); einde van schijf 1 (blok A91) tot het begin van schijf 2 (blok A92). Als RAID 0 gebruikt zou worden, dan zouden schijf 0 en schijf 2 afgekapt worden tot 28 blokken, de grootte van de kleinste schijf in de array (schijf 1) voor een totale grootte van 84 blokken.
Sommige RAID-controllers gebruiken JBOD om te praten over het werken aan schijven zonder RAID-functies. Elke schijf wordt afzonderlijk in het besturingssysteem weergegeven. Deze JBOD is niet hetzelfde als aaneenschakeling.
Veel Linux-systemen gebruiken de termen "lineaire modus" of "append modus". De Mac OS X 10.4 implementatie - een "Concatenated Disk Set" genaamd - laat de gebruiker geen bruikbare gegevens achter op de resterende schijven als een schijf in een aaneengeschakelde set uitvalt, hoewel de schijven anders werken zoals hierboven beschreven.
Aaneenschakeling is een van de toepassingen van de Logical Volume Manager in Linux. Het kan worden gebruikt om virtuele schijven te maken.
Aandrijving Kloon
De meeste moderne harde schijven hebben een standaard die Self-Monitoring, Analysis and Reporting Technology (S.M.A.R.T) wordt genoemd. SMART maakt het mogelijk om bepaalde zaken op een harde schijf te monitoren. Bepaalde controllers maken het mogelijk om een enkele harde schijf te vervangen voordat deze uitvalt, bijvoorbeeld omdat S.M.A.R.T of een andere schijf-test te veel corrigeerbare fouten meldt. Om dit te doen, kopieert de controller alle gegevens naar een hot spare drive. Hierna kan de schijf worden vervangen door een andere (die gewoon de nieuwe hot spare wordt).
Verschillende opstellingen
De opstelling van de schijven en de manier waarop ze de bovenstaande technieken gebruiken, heeft invloed op de prestaties en de betrouwbaarheid van het systeem. Wanneer er meer schijven worden gebruikt, heeft een van de schijven een grotere kans om te falen. Daarom moeten er mechanismen worden gebouwd om fouten te kunnen opsporen en herstellen. Dit maakt het hele systeem betrouwbaarder, omdat het in staat is om te overleven en de storing te repareren.

Basis: eenvoudige RAID-niveaus
RAID-niveaus in gemeenschappelijk gebruik
RAID 0 "striping"
RAID 0 is niet echt RAID omdat het niet overbodig is. Met RAID 0 worden schijven gewoon in elkaar gezet om een grote schijf te maken. Dit wordt "striping" genoemd. Wanneer één schijf uitvalt, mislukt de hele array. Daarom wordt RAID 0 zelden gebruikt voor belangrijke gegevens, maar het lezen en schrijven van gegevens van de schijf kan sneller gaan met striping omdat elke schijf een deel van het bestand tegelijkertijd leest.
Bij RAID 0 worden schijfblokken die achter elkaar komen meestal op verschillende schijven geplaatst. Om deze reden moeten alle schijven die door een RAID 0 worden gebruikt dezelfde grootte hebben.
RAID 0 wordt vaak gebruikt voor Swapspace op Linux of Unix-achtige besturingssystemen.
RAID 1 "spiegeling"
Bij RAID 1 worden twee schijven samengevoegd. Beide hebben dezelfde gegevens, de ene "spiegelt" de andere. Dit is een eenvoudige, snelle configuratie, of het nu met een hardwarecontroller of met software is geïmplementeerd.
RAID 5 "striping met verdeelde pariteit".
RAID-niveau 5 wordt waarschijnlijk het meest gebruikt. Er zijn minstens drie harde schijven nodig om een RAID 5-opslagarray te bouwen. Elk blok gegevens wordt op drie verschillende plaatsen opgeslagen. Twee van deze plaatsen slaan het blok op zoals het is, de derde slaat een checksum op. Deze checksum is een speciaal geval van een Reed-Solomon code die alleen bitwise toevoeging gebruikt. Meestal wordt het berekend met de XOR-methode. Omdat deze methode symmetrisch is, kan het ene verloren gegane datablok opnieuw worden opgebouwd uit het andere datablok en de checksum. Voor elk blok zal een andere schijf het pariteitsblok bevatten dat de checksum bevat. Dit wordt gedaan om de redundantie te verhogen. Elke schijf kan falen. In het algemeen zal er één schijf zijn die de checksum bevat, dus de totale bruikbare capaciteit zal die van alle schijven zijn, behalve één. De grootte van de resulterende logische schijf zal de grootte van alle schijven samen zijn, behalve één schijf die de pariteitsinformatie bevat.
Dit is natuurlijk langzamer dan RAID-niveau 1, omdat bij elk schrijven alle schijven moeten worden gelezen om de pariteitsinformatie te berekenen en bij te werken. De leesprestatie van RAID 5 is bijna net zo goed als RAID 0 voor hetzelfde aantal schijven. Met uitzondering van de pariteitsblokken volgt de verdeling van de gegevens over de schijven hetzelfde patroon als RAID 0. De reden dat RAID 5 iets langzamer is, is dat de schijven over de pariteitsblokken heen moeten springen.
Een RAID 5 met een defecte schijf zal blijven werken. Hij staat in gedegradeerde modus. Een gedegradeerde RAID 5 kan erg langzaam zijn. Om deze reden wordt vaak een extra schijf toegevoegd. Dit wordt hot spare disk genoemd. Als een schijf kapot gaat, kan de data direct weer op de extra schijf worden opgebouwd. RAID 5 kan ook vrij eenvoudig in software worden uitgevoerd.
Hoofdzakelijk vanwege prestatieproblemen van mislukte RAID 5-arrays, hebben sommige database-experts een groep gevormd met de naam BAARF - de strijd tegen elke Raid Five.
Als het systeem uitvalt terwijl er actief wordt geschreven, kan de pariteit van een streep inconsistent worden met de gegevens. Als dit niet wordt gerepareerd voordat een schijf of blokkade uitvalt, kan er gegevensverlies optreden. Een onjuiste pariteit zal worden gebruikt om het ontbrekende blok in die strip te reconstrueren. Dit probleem wordt ook wel het "schrijfgat" genoemd. Caches op batterijen en soortgelijke technieken worden vaak gebruikt om de kans hierop te verkleinen.
Foto's
· 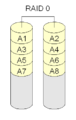
RAID 0 zet gewoon de verschillende blokken op de verschillende schijven. Er is geen redundantie.
· 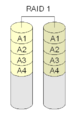
Met Raid 1 is elk blok op beide schijven aanwezig.
· 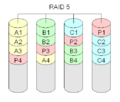
RAID 5 berekent speciale controlesommen voor de gegevens. Zowel de blokken met de checksum als die met de gegevens worden verdeeld over alle schijven.
RAID-niveaus minder gebruikt
RAID 2
Dit werd gebruikt met zeer grote computers. Voor het gebruik van RAID Level 2 zijn speciale dure schijven en een speciale controller nodig. De gegevens worden verdeeld op het bitniveau (alle andere niveaus gebruiken byte-niveau acties). Er worden speciale berekeningen gedaan. De gegevens worden opgesplitst in statische sequenties van bits. 8 databits en 2 pariteitsbits worden samengevoegd. Vervolgens wordt een Hamming code berekend. De fragmenten van de Hamming code worden vervolgens verdeeld over de verschillende schijven.
RAID 2 is het enige RAID-niveau dat fouten kan herstellen, de andere RAID-niveaus kunnen deze alleen detecteren. Als ze merken dat de benodigde informatie niet klopt, dan bouwen ze die gewoon weer op. Dit wordt gedaan met berekeningen, waarbij gebruik wordt gemaakt van informatie op de andere schijven. Als die informatie ontbreekt of verkeerd is, kunnen ze niet veel doen. Omdat het gebruik maakt van Hamming codes, kan RAID 2 erachter komen welk deel van de informatie verkeerd is, en alleen dat deel corrigeren.
RAID 2 heeft minstens 10 schijven nodig om te werken. Vanwege de complexiteit en de behoefte aan zeer dure en speciale hardware wordt RAID 2 niet meer zo veel gebruikt.
RAID 3 "striping met specifieke pariteit".
Raid Level 3 lijkt veel op RAID Level 0. Er wordt een extra schijf toegevoegd om de pariteitsinformatie op te slaan. Dit wordt gedaan door de waarde van een blok op de andere schijven bitsgewijs toe te voegen. De pariteitsinformatie wordt opgeslagen op een aparte (speciale) schijf. Dit is niet goed, want als de pariteitsschijf crasht, gaat de pariteitsinformatie verloren.
RAID-niveau 3 wordt meestal gedaan met minstens 3 schijven. Een opstelling met twee schijven is identiek aan een RAID-niveau 0.
RAID 4 "striping met specifieke pariteit".
Dit is zeer vergelijkbaar met RAID 3, behalve dat de pariteitsinformatie wordt berekend over grotere blokken, en niet over enkele bytes. Dit lijkt op RAID 5. Er zijn minstens drie schijven nodig voor een RAID 4-array.
RAID 6
RAID-niveau 6 was geen origineel RAID-niveau. Het voegt een extra pariteitsblok toe aan een RAID 5-array. Het heeft ten minste vier schijven nodig (twee schijven voor de capaciteit, twee schijven voor de redundantie). RAID 5 kan worden gezien als een speciaal geval van een Reed-Solomon-code. RAID 5 is een speciaal geval, maar hoeft alleen te worden toegevoegd in het Galoisveld GF(2). Dit is eenvoudig te doen met XOR's. RAID 6 breidt deze berekeningen uit. Het is geen speciaal geval meer en alle berekeningen moeten worden uitgevoerd. Bij RAID 6 wordt een extra checksum (polynomiaal genoemd) gebruikt, meestal van GF (28). Met deze aanpak is het mogelijk om zich te beschermen tegen een willekeurig aantal mislukte schijven. RAID 6 is voor het gebruik van twee checksums ter bescherming tegen het verlies van twee schijven.
Net als bij RAID 5 staan pariteit en data op verschillende schijven voor elk blok. De twee pariteitsblokken staan ook op verschillende schijven.
Er zijn verschillende manieren om RAID 6 te doen. Ze zijn verschillend in hun schrijfprestatie, en in hoeveel berekeningen er nodig zijn. Omdat ze sneller kunnen schrijven, zijn er meestal meer berekeningen nodig.
RAID 6 is langzamer dan RAID 5, maar het laat de RAID toe door te gaan met twee defecte schijven. RAID 6 wordt populair omdat het mogelijk is om een array opnieuw op te bouwen na een storing van een enkele schijf, zelfs als een van de resterende schijven een of meer slechte sectoren heeft.
Foto's
· 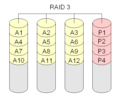
RAID 3 lijkt veel op RAID-niveau 0. Er wordt een extra schijf toegevoegd die een checksum bevat voor elk blok gegevens.
· 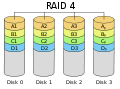
RAID 4 is vergelijkbaar met RAID-niveau 3, maar berekent de pariteit over grotere gegevensblokken
· 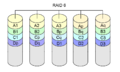
RAID 6 is vergelijkbaar met RAID 5, maar het berekent twee verschillende checksums. Dit maakt het mogelijk om twee schijven te laten falen, zonder verlies van gegevens.
Niet-standaard RAID-niveaus
Dubbele pariteit / Diagonale pariteit
RAID 6 maakt gebruik van twee pariteitsblokken. Deze worden op een speciale manier berekend over een polynoom. Dubbele pariteit RAID (ook wel diagonale pariteit RAID genoemd) gebruikt voor elk van deze pariteitsblokken een andere polynoom. Onlangs heeft de branchevereniging die RAID heeft gedefinieerd gezegd dat dubbele pariteit RAID een andere vorm van RAID 6 is.
RAID-DP
RAID-DP is een andere manier om dubbele pariteit te hebben.
RAID 1,5
RAID 1.5 (niet te verwarren met RAID 15, dat is anders) is een eigen RAID-implementatie. Net als RAID 1 gebruikt het slechts twee schijven, maar het doet zowel striping als mirroring (vergelijkbaar met RAID 10). De meeste dingen worden gedaan in hardware.
RAID 5E, RAID 5EE en RAID 6E
RAID 5E, RAID 5EE en RAID 6E (met de toegevoegde E voor Enhanced) verwijzen over het algemeen naar verschillende soorten RAID 5 of RAID 6 met een hot spare. Bij deze uitvoeringen is de hot spare drive geen fysieke drive. Het bestaat eerder in de vorm van vrije ruimte op de schijven. Dit verhoogt de prestaties, maar het betekent dat een hot spare niet kan worden gedeeld tussen verschillende arrays. Het schema is rond 2001 geïntroduceerd door IBM ServeRAID.
RAID 7
Dit is een eigen implementatie. Het voegt caching toe aan een RAID 3 of RAID 4 array.
Intel Matrix RAID
Sommige Intel-hoofdkaarten hebben een RAID-chip die deze functie heeft. Het gebruikt twee of drie schijven, en partitioneert ze dan gelijkelijk om een combinatie van RAID 0, RAID 1, RAID 5 of RAID 1+0 niveaus te vormen.
Linux MD RAID-stuurprogramma
Dit is de naam voor de driver die het mogelijk maakt om software RAID te doen met Linux. Naast de normale RAID-niveaus 0-6 heeft het ook een RAID 10-implementatie. Sinds Kernel 2.6.9 is RAID 10 een enkel niveau. De implementatie heeft enkele niet-standaard functies.
RAID Z
Sun heeft een bestandssysteem geïmplementeerd dat ZFS heet. Dit bestandssysteem is geoptimaliseerd voor het verwerken van grote hoeveelheden gegevens. Het bevat een Logical Volume Manager. Het bevat ook een functie genaamd RAID-Z. Het vermijdt het probleem dat RAID 5-schrijfgat heet omdat het een copy-on-write beleid heeft: Het overschrijft de gegevens niet direct, maar schrijft nieuwe gegevens op een nieuwe locatie op de schijf. Wanneer het schrijven succesvol was, wordt de oude data gewist. Het vermijdt de noodzaak van read-modify-write operaties voor kleine schrijfsels, omdat het alleen full-stripes schrijft. Kleine blokken worden gespiegeld in plaats van beschermd tegen pariteit, wat mogelijk is omdat het bestandssysteem weet hoe de opslag is georganiseerd. Het kan dus extra ruimte toewijzen als dat nodig is. Er is ook RAID-Z2 dat twee vormen van pariteit gebruikt om resultaten te bereiken die vergelijkbaar zijn met RAID 6: de mogelijkheid om tot twee schijfdefecten te overleven zonder data te verliezen.
Foto's
· 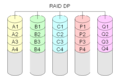
Diagram van een RAID DP (Double Parity) opstelling.
· 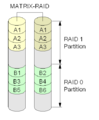
Een Matrix RAID-opstelling.
Aansluiting bij RAID-niveaus
Met RAID kunnen verschillende schijven in elkaar worden gezet om een logische schijf te krijgen. De gebruiker zal alleen de logische schijf zien. Elk van de bovengenoemde RAID-niveaus heeft goede en slechte punten. Maar RAID kan ook werken met logische schijven. Op die manier kan een van de bovenstaande RAID-levels gebruikt worden met een set logische schijven. Veel mensen noteren het door de nummers bij elkaar te schrijven. Soms schrijven ze een '+' of een '&' tussendoor. Veel voorkomende combinaties (met twee niveaus) zijn de volgende:
- RAID 0+1: Twee of meer RAID 0-arrays worden gecombineerd tot een RAID 1-array; dit wordt een Spiegel van strepen genoemd.
- RAID 1+0: Zelfde als RAID 0+1, maar RAID-niveaus omgekeerd; Stripe of Mirrors. Dit maakt schijffouten zeldzamer dan RAID 0+1 hierboven.
- RAID 5+0: Streep meerdere RAID 5's met een RAID 0. Een schijf van elke RAID 5 kan falen, maar maakt van die RAID 5 het enige punt van falen; als een andere schijf van die array faalt, gaan alle gegevens van de array verloren.
- RAID 5+1: Spiegel een set van RAID 5: In een situatie waarin de RAID uit zes schijven bestaat, kunnen er drie defect raken (zonder dat er gegevens verloren gaan).
- RAID 6+0: Streep meerdere RAID 6-arrays over een RAID 0; twee schijven van elke RAID 6 kunnen falen zonder verlies van gegevens.
Met zes schijven van elk 300 GB, een totale capaciteit van 1,8TB, is het mogelijk om een RAID 5 te maken, met 1,5 TB bruikbare ruimte. In die array kan één schijf uitvallen zonder dat er gegevens verloren gaan. Met RAID 50 wordt de ruimte gereduceerd tot 1,2 TB, maar één schijf van elke RAID 5 kan uitvallen, plus er is een merkbare toename van de prestaties. RAID 51 verkleint de bruikbare grootte tot 900 GB, maar staat toe dat drie schijven het laten afweten.
· 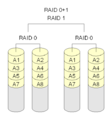
RAID 0+1: Verschillende RAID 0-arrays worden gecombineerd met een RAID 1
· 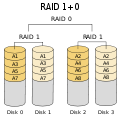
RAID 1+0: robuuster dan RAID 0+1; ondersteunt meerdere aandrijvingsfouten, zolang er geen twee aandrijvingen zijn die een spiegel doen falen.
· 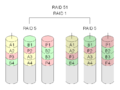
RAID 5+1: Elke drie schijven hiervan kunnen uitvallen, zonder verlies van gegevens.
Een RAID maken
Er zijn verschillende manieren om een RAID te maken. Het kan zowel met software als met hardware.
Software RAID
Een RAID kan op twee verschillende manieren met software worden gemaakt. In het geval van Software RAID worden de schijven aangesloten zoals normale harde schijven. Het is de computer die de RAID doet werken. Dit betekent dat voor elke toegang de CPU ook de berekeningen voor de RAID moet doen. De berekeningen voor RAID 0 of RAID 1 zijn eenvoudig. De berekeningen voor RAID 5, RAID 6 of een van de gecombineerde RAID-niveaus kunnen echter veel werk zijn. In een software RAID kan het automatisch opstarten van een mislukte array moeilijk zijn. Tot slot is de manier waarop RAID in software wordt gedaan afhankelijk van het gebruikte besturingssysteem; het is over het algemeen niet mogelijk om een Software RAID-array te herbouwen met een ander besturingssysteem. Besturingssystemen gebruiken meestal harde schijf partities in plaats van hele harde schijven om RAID-arrays te maken.
Hardware RAID
Een RAID kan ook met hardware worden gemaakt. In dit geval wordt een speciale schijfcontroller gebruikt; deze controllerkaart verbergt het feit dat hij RAID doet voor het besturingssysteem en de gebruiker. De berekeningen van de checksum-informatie en andere RAID-gerelateerde berekeningen worden uitgevoerd op een speciale microchip in die controller. Dit maakt de RAID onafhankelijk van het besturingssysteem. Het besturingssysteem zal de RAID niet zien, het zal een enkele schijf zien. Verschillende fabrikanten doen de RAID op verschillende manieren. Dit betekent dat een RAID die met de ene hardware RAID-controller is gebouwd niet door een andere RAID-controller van een andere fabrikant kan worden gereviseerd. Hardware RAID-controllers zijn vaak duur in aanschaf.
Hardware-ondersteunde RAID
Dit is een mix tussen hardware RAID en software RAID. Hardware-ondersteunde RAID maakt gebruik van een speciale controllerchip (zoals hardware RAID), maar deze chip kan niet veel bewerkingen uitvoeren. Hij is alleen actief als het systeem wordt gestart; zodra het besturingssysteem volledig is geladen, is deze configuratie als software RAID. Sommige moederborden hebben RAID-functies voor de aangesloten schijven; meestal worden deze RAID-functies uitgevoerd als hardware-ondersteunde RAID. Dit betekent dat er speciale software nodig is om deze RAID-functies te kunnen gebruiken en om te kunnen herstellen van een defecte schijf.
Verschillende termen met betrekking tot hardwarestoringen
Er zijn verschillende termen die worden gebruikt wanneer er over hardwarestoringen wordt gesproken:
Storingspercentage
Het storingspercentage is hoe vaak een systeem uitvalt. De gemiddelde tijd tot falen (MTTF) of de gemiddelde tijd tussen falen (MTBF) van een RAID-systeem is dezelfde als die van zijn componenten. Een RAID-systeem kan zich immers niet beschermen tegen storingen van zijn individuele harde schijven. De meer gecompliceerde soorten RAID (alles wat verder gaat dan "striping" of "aaneenschakeling") kan helpen om de gegevens intact te houden, zelfs als een individuele harde schijf uitvalt.
Gemiddelde tijd tot gegevensverlies
De gemiddelde time to data loss (MTTDL) geeft de gemiddelde tijd aan voordat er een verlies van gegevens plaatsvindt in een bepaalde array. De gemiddelde tijd tot gegevensverlies van een bepaalde RAID kan hoger of lager zijn dan die van de harde schijven. Dit is afhankelijk van het type RAID dat wordt gebruikt.
Gemiddelde tijd tot herstel
Arrays die redundantie hebben, kunnen zich herstellen van sommige mislukkingen. De gemiddelde tijd die nodig is om te herstellen laat zien hoe lang het duurt voordat een defecte array weer in zijn normale staat is. Dit voegt zowel de tijd toe om een defecte schijf te vervangen als de tijd om de array opnieuw op te bouwen (d.w.z. om gegevens te repliceren voor redundantie).
Onherstelbare bitfoutpercentage
De unrecoverable bit error rate (UBE) vertelt hoe lang een schijfstation niet in staat zal zijn om gegevens te herstellen na het gebruik van cyclische redundantiecontrole (CRC) codes en meerdere retries.
Problemen met RAID
Er zijn ook bepaalde problemen met de ideeën of de technologie achter RAID:
Schijven toevoegen op een later tijdstip
Bepaalde RAID-niveaus maken het mogelijk om de array uit te breiden door eenvoudigweg harde schijven toe te voegen, op een later tijdstip. Informatie zoals pariteitsblokken wordt vaak verspreid over meerdere schijven. Het toevoegen van een schijf aan de array betekent dat een reorganisatie nodig is. Zo'n reorganisatie is als een heropbouw van de array, het kan lang duren. Wanneer dit gedaan is, kan het zijn dat de extra ruimte nog niet beschikbaar is, omdat zowel het bestandssysteem op de array, als het besturingssysteem hierover verteld moet worden. Sommige bestandssystemen ondersteunen niet om te worden gekweekt nadat ze zijn gemaakt. In zo'n geval moet er een back-up worden gemaakt van alle gegevens, moet de array opnieuw worden gemaakt met de nieuwe lay-out en moeten de gegevens erop worden teruggezet.
Een andere optie om opslag toe te voegen is het creëren van een nieuwe array en het laten afhandelen van de situatie door een logische volumemanager. Dit maakt het mogelijk om bijna elk RAID-systeem te laten groeien, zelfs RAID1 (dat op zichzelf beperkt is tot twee schijven).
Gekoppelde mislukkingen
Het foutcorrectiemechanisme in RAID gaat ervan uit dat storingen van de aandrijvingen onafhankelijk zijn. Het is mogelijk om te berekenen hoe vaak een apparaat kan falen en om de array zo te rangschikken dat het verlies van gegevens zeer onwaarschijnlijk is.
In de praktijk werden de aandrijvingen echter vaak samen gekocht. Ze hebben ongeveer dezelfde leeftijd en zijn op dezelfde manier gebruikt (slijtage genoemd). Veel aandrijvingen gaan kapot door mechanische problemen. Hoe ouder een aandrijving is, hoe meer versleten de mechanische onderdelen ervan zijn. Mechanische onderdelen die oud zijn, lopen meer kans om te falen dan die welke jonger zijn. Dit betekent dat aandrijvingsfouten niet langer statistisch onafhankelijk zijn. In de praktijk bestaat de kans dat een tweede schijf ook uitvalt voordat de eerste is hersteld. Dit betekent dat het verlies van gegevens in de praktijk aanzienlijk kan zijn.
Atomiciteit
Een ander probleem dat zich ook bij RAID-systemen voordoet, is dat applicaties een zogenaamde Atomiciteit verwachten: Of alle gegevens worden geschreven, of geen enkele. Het schrijven van de gegevens staat bekend als een transactie.
In RAID-arrays worden de nieuwe gegevens meestal geschreven op de plaats waar de oude gegevens zich bevonden. Dit is bekend geworden als update in-place. Jim Gray, een database onderzoeker schreef in 1981 een paper waarin hij dit probleem beschreef.
Zeer weinig opslagsystemen laten atomaire schrijfsemantiek toe. Wanneer een object naar schijf wordt geschreven, zal een RAID-opslagapparaat meestal alle kopieën van het object parallel schrijven. Heel vaak is er maar één processor verantwoordelijk voor het schrijven van de gegevens. In zo'n geval zal het schrijven van gegevens naar de verschillende schijven overlappen. Dit staat bekend als overlappend schrijven of verspringend schrijven. Een fout die optreedt tijdens het schrijfproces kan er dus voor zorgen dat de overtollige kopieën in verschillende toestanden blijven staan. Erger nog, het kan zijn dat de kopieën noch in de oude, noch in de nieuwe staat blijven. Bij het loggen wordt er echter van uitgegaan dat de originele gegevens in de oude of de nieuwe staat zijn. Dit maakt het mogelijk om de logische verandering te backuppen, maar weinig opslagsystemen bieden een atomaire schrijfsemantiek op een RAID-schijf.
Het gebruik van een schrijfgeheugen op batterijen kan dit probleem oplossen, maar alleen in het geval van een stroomstoring.
Transactie-ondersteuning is niet in alle hardware RAID-controllers aanwezig. Daarom bevatten veel besturingssystemen het om te beschermen tegen gegevensverlies tijdens een onderbroken schrijven. Novell Netware, te beginnen met versie 3.x, bevatte een systeem voor het traceren van transacties. Microsoft introduceerde transactietracking via de journaling-functie in NTFS. Het NetApp WAFL-bestandssysteem lost dit op door de gegevens nooit bij te werken, zoals ZFS dat doet.
Onherstelbare gegevens
Sommige sectoren op een harde schijf kunnen onleesbaar zijn geworden door een fout. Sommige RAID-implementaties kunnen met deze situatie omgaan door de gegevens naar elders te verplaatsen en de sector op de schijf als slecht te markeren. Dit gebeurt bij ongeveer 1 bit in 1015 in enterprise-class schijven, en 1 bit in 1014 in gewone schijven. Schijfcapaciteiten nemen gestaag toe. Dit kan betekenen dat een RAID soms niet kan worden herbouwd, omdat zo'n fout wordt gevonden als de array wordt herbouwd na een schijfstoring. Bepaalde technologieën zoals RAID 6 proberen dit probleem aan te pakken, maar ze lijden onder een zeer hoge schrijfboete, met andere woorden, het schrijven van gegevens wordt erg langzaam.
Schrijf cache-betrouwbaarheid
Het schijfsysteem kan de schrijfoperatie bevestigen zodra de gegevens in de cache staan. Het hoeft niet te wachten tot de gegevens fysiek zijn geschreven. Elke stroomonderbreking kan dan echter een aanzienlijk gegevensverlies betekenen van de gegevens die in een dergelijke cache in de wachtrij staan.
Met hardware RAID kan een batterij worden gebruikt om deze cache te beschermen. Dit lost vaak het probleem op. Als de stroom uitvalt, kan de controller de cache afmaken als de stroom weer terug is. Deze oplossing kan echter nog steeds mislukken: de batterij kan versleten zijn, de stroom kan te lang uitgevallen zijn, de schijven kunnen naar een andere controller worden verplaatst, de controller zelf kan defect raken. Bepaalde systemen kunnen periodieke accucontroles uitvoeren, maar deze gebruiken de accu zelf en laten deze in een staat staan waarin deze niet volledig is opgeladen.
Compatibiliteit van de apparatuur
De schijfformaten op verschillende RAID-controllers zijn niet noodzakelijkerwijs compatibel. Daarom is het misschien niet mogelijk om een RAID-array op verschillende hardware te lezen. Daarom kan het voor een storing in de niet-schijfhardware nodig zijn om identieke hardware te gebruiken, of een back-up te maken, om de gegevens te herstellen.
Wat RAID wel en niet kan doen
Deze gids is ontleend aan een draadje uit een RAID-gerelateerd forum. Dit werd gedaan om de voor- en nadelen van de keuze voor RAID aan te geven. Het is gericht op mensen die RAID willen kiezen voor ofwel prestatieverhoging ofwel redundantie. Het bevat links naar andere threads in het forum met door gebruikers gegenereerde anekdotische beoordelingen van hun RAID-ervaringen.
Wat RAID kan doen
- RAID kan de uptime beschermen. RAID-niveaus 1, 0+1/10, 5 en 6 (en hun varianten zoals 50 en 51) maken een mechanische storing van de harde schijf goed. Zelfs nadat de schijf is uitgevallen, kunnen de gegevens op de array nog steeds worden gebruikt. In plaats van een tijdrovende restore van tape, DVD of andere langzame back-upmedia, maakt RAID het mogelijk om gegevens te herstellen naar een vervangende schijf van de andere leden van de array. Tijdens dit herstelproces is het beschikbaar voor gebruikers in een gedegradeerde staat. Dit is zeer belangrijk voor bedrijven, aangezien downtime snel leidt tot verlies van verdiencapaciteit. Voor thuisgebruikers kan het de uptime van grote media-opslagarrays beschermen, wat een tijdrovende restauratie van tientallen dvd's of nogal wat tapes zou vereisen in het geval dat een schijf uitvalt die niet door redundantie wordt beschermd.
- RAID kan de prestaties in bepaalde toepassingen verhogen. RAID-niveaus 0, 5 en 6 gebruiken allemaal striping. Hierdoor kunnen meerdere spindels de overdrachtsnelheden voor lineaire overdrachten verhogen. Toepassingen van het type werkstation werken vaak met grote bestanden. Ze hebben veel baat bij disk striping. Voorbeelden van dergelijke toepassingen zijn die waarbij gebruik wordt gemaakt van video- of audiobestanden. Deze doorvoer is ook nuttig bij schijf-tot-schijf back-ups. RAID 1 en andere op striping gebaseerde RAID-niveaus kunnen de prestaties verbeteren voor toegangspatronen met veel gelijktijdige willekeurige toegangen, zoals die welke worden gebruikt door een multi-user database.
Wat RAID niet kan doen
- RAID kan de gegevens op de array niet beschermen. Een RAID-array heeft één bestandssysteem. Dit creëert een enkel storingspunt. Er zijn veel dingen die met dit bestandssysteem kunnen gebeuren, behalve fysieke schijffouten. RAID kan zich niet verdedigen tegen deze bronnen van gegevensverlies. RAID zal een virus niet tegenhouden om gegevens te vernietigen. RAID zal corruptie niet voorkomen. RAID slaat geen gegevens op wanneer een gebruiker deze wijzigt of per ongeluk verwijdert. RAID beschermt geen gegevens tegen hardwarefouten van andere componenten dan fysieke schijven. RAID beschermt geen gegevens tegen natuurrampen of door de mens veroorzaakte rampen zoals branden en overstromingen. Om gegevens te beschermen, moet er een back-up worden gemaakt op verwijderbare media, zoals dvd, tape of een externe harde schijf. De back-up moet op een andere plaats worden bewaard. RAID alleen zal niet voorkomen dat een ramp, wanneer (niet als) deze zich voordoet, verandert in gegevensverlies. Rampen kunnen niet worden voorkomen, maar met back-ups kan gegevensverlies wel worden voorkomen.
- RAID kan het herstel van rampen niet vereenvoudigen. Bij het uitvoeren van een enkele schijf kan de schijf door de meeste besturingssystemen worden gebruikt, aangezien deze met een gemeenschappelijk apparaatstuurprogramma worden geleverd. De meeste RAID-controllers hebben echter speciale stuurprogramma's nodig. Herstelgereedschappen die werken met enkele schijven op generieke controllers hebben speciale stuurprogramma's nodig om toegang te krijgen tot gegevens op RAID-arrays. Als deze herstelprogramma's slecht gecodeerd zijn en niet voorzien in extra stuurprogramma's, dan zal een RAID-array waarschijnlijk ontoegankelijk zijn voor dat herstelprogramma.
- RAID kan niet in alle toepassingen een prestatieboost geven. Deze stelling geldt vooral voor typische gebruikers en gamers van desktoptoepassingen. Voor de meeste bureaubladtoepassingen en games zijn de bufferstrategie en het zoeken naar prestaties van de schijf(en) belangrijker dan de ruwe doorvoer. Het verhogen van de ruwe doorvoersnelheid laat weinig winst zien voor zulke gebruikers, omdat de meeste bestanden die ze benaderen meestal toch al heel klein zijn. Schijfstriping met behulp van RAID 0 verhoogt de lineaire overdrachtsprestatie, niet de buffer- en zoekprestatie. Het resultaat is dat schijfstriping met RAID 0 weinig tot geen prestatiewinst laat zien in de meeste bureaubladtoepassingen en games, hoewel er uitzonderingen zijn. Voor desktopgebruikers en gamers met hoge prestaties als doel, is het beter om een snellere, grotere en duurdere enkele schijf te kopen dan twee langzamere/kleine schijven in RAID 0 te gebruiken. Zelfs het draaien van de nieuwste, grootste en grootste schijven in RAID-0 zal de prestaties waarschijnlijk niet meer dan 10% verhogen, en de prestaties kunnen dalen in sommige toegangspatronen, met name in games.
- Het is moeilijk om RAID te verplaatsen naar een nieuw systeem. Met een enkele schijf is het relatief eenvoudig om de schijf te verplaatsen naar een nieuw systeem. Het kan eenvoudig worden aangesloten op het nieuwe systeem, als het dezelfde interface beschikbaar heeft. Dit is echter niet zo eenvoudig met een RAID-array. Er is een bepaald soort Metadata dat zegt hoe de RAID is ingesteld. Een RAID BIOS moet in staat zijn om deze metadata te lezen, zodat het de array met succes kan opbouwen en toegankelijk kan maken voor een besturingssysteem. Aangezien RAID-controllermakers verschillende formaten gebruiken voor hun metadata (zelfs controllers van verschillende families van dezelfde fabrikant kunnen incompatibele metadataformaten gebruiken) is het bijna onmogelijk om een RAID-array te verplaatsen naar een andere controller. Bij het verplaatsen van een RAID-array naar een nieuw systeem moeten er ook plannen worden gemaakt om de controller te verplaatsen. Met de populariteit van de geïntegreerde RAID-controllers op het moederbord is dit uiterst moeilijk. Over het algemeen is het mogelijk om de RAID-array-leden en controllers samen te verplaatsen. Software RAID in Linux en Windows Server Producten kan ook werken rond deze beperking, maar software RAID heeft andere (meestal prestatiegerelateerde).
Voorbeeld
De meest gebruikte RAID-niveaus zijn RAID 0, RAID 1 en RAID 5. Stel dat er een 3-schijf-opstelling is, met 3 identieke schijven van elk 1 TB, en de kans op uitval van een schijf voor een bepaalde tijdspanne is 1%.
| RAID-niveau | Bruikbare capaciteit | Waarschijnlijkheid van mislukking uitgedrukt in procenten | Waarschijnlijkheid van mislukking 1 in ... gevallen mislukt |
| 0 | 3 TB | 2,9701% | 34 |
| 1 | 1 TB | 0,0001% | 1 miljoen |
| 5 | 2 TB | 0,0298% | 3356 |
Auteur
AlegsaOnline.com Redundant array of independent disks Leandro Alegsa
URL: https://nl.alegsaonline.com/art/80859
Bronnen
- www-2.cs.cmu.edu : ""A Case for Redundant Arrays of Inexpensive Disks" - Patterson, Gibson, Katz"
- thomason.org : "RAID: High-Performance, Reliable Secondary Storage"
- baarf.com : "BAARF - Battle Against Any Raid Five"
- media.netapp.com : "RAID-DP™: Network Appliance™ implementation of RAID Double Parity for data protection, a high speed implementation of RAID 6"
- nasi.com : "IBM X-Architecture Technology 2001:A design blueprint for Intel processor-based servers"
- pcguide.com : "RAID Level 7"
- cgi.cse.unsw.edu.au : "Linux RAID 10 driver"
- linux-raid.osdl.org : "Main Page - Linux-raid"
- blogs.sun.com : "RAID-Z : Jeff Bonwick's Blog"
- blogs.sun.com : "Adam Leventhal's Weblog"
- research.microsoft.com : "Empirical Measurements of Disk Failure Rates and Error Rates"
- usenix.org : "Disk Failures in the Real World: What Does an MTTF of 1,000,000 Hours Mean to You?"
- research.microsoft.com : "The Transaction Concept: Virtues and Limitations (Invited Paper)¦format=pdf"
- informatik.uni-trier.de : "VLDB 1981"
- arxiv.org : "Empirical Measurements of Disk Failure Rates and Error Rates"