Bio-informatica (computationale biologie): wat is het en hoe werkt het?
Leer wat bio‑informatica (computationele biologie) is, hoe computers DNA en moleculaire data analyseren en welke toepassingen dit heeft in onderzoek, geneeskunde en biotechnologie.
Bio-informatica of computationele biologie is de studie van grote hoeveelheden biologische informatie. Meestal gaat het om moleculen zoals DNA. Het gebeurt meestal met behulp van computers.
Afbeeldingengalerij
10 Afbeeldingen








Wat is het precies?
Kort gezegd verbindt bio-informatica biologie en informatica. In plaats van elk experiment alleen met nat-chemische technieken te analyseren, gebruiken onderzoekers algoritmen, statistiek en software om grote datasets te verwerken, te visualiseren en te interpreteren. Die datasets ontstaan bijvoorbeeld door DNA-/RNA-sequencing, eiwitmeting, microscopie of populatieonderzoek.
Belangrijke toepassingsgebieden
- Genomics: bestuderen van volledige genomen (DNA) van organismen; identificatie van genen en varianten.
- Transcriptomics: analyseren van genexpressie (RNA) om te zien welke genen actief zijn onder bepaalde omstandigheden.
- Proteomics: onderzoek naar eiwitten: welke aanwezig zijn, in welke hoeveelheden en hoe ze interageren.
- Metagenomics en ecologie: analyse van DNA uit omgevingsmonsters (bv. bodem, water) om soorten samenstellingen te bepalen.
- Structurele bio-informatica: voorspellen en analyseren van 3D-structuren van biomoleculen.
- Epidemiologie en volksgezondheid: volgen van ziekte-uitbraken (bv. virale varianten), contacttracing en surveillancesystemen.
Hoe werkt bio-informatica? Methoden en workflow
Een typische analyse doorloopt meerdere stappen:
- Dataverzameling: moderne sequencers en instrumenten genereren ruwe data (bijv. reads uit sequencers).
- Preprocessing: kwaliteitscontrole en filtering van ruwe data (bv. verwijdering van error-reads).
- Mapping en assemblage: reads op een referentiegenoom uitlijnen of zelf een nieuw genoom samenstellen.
- Analyse: variantdetectie (SNPs, indels), genannotatie, differentiële genexpressie, interactienetwerken, phylogenie, of structurele voorspellingen.
- Interpretatie en validatie: biologische betekenis vaststellen en waar mogelijk experimenteel bevestigen.
Veelgebruikte tools en bestandsformaten
Bio-informatici gebruiken zowel kant-en-klare programma’s als eigen scripts. Enkele voorbeelden:
- Aligners en assemblers: BWA, Bowtie, HISAT2, SPAdes.
- Kwaliteitscontrole en preprocessing: FastQC, Trimmomatic.
- Variant calling en verwerking: GATK, SAMtools.
- Vergelijking en annotatie: BLAST, MAFFT, Clustal.
- Machine learning / AI: scikit-learn, TensorFlow, PyTorch voor patroonherkenning en voorspellingen.
- Programmeertalen: Python (Biopython), R (Bioconductor) en shell-scripting voor pipelines.
Veelgebruikte bestandsformaten zijn FASTA/FASTQ (sequenties en reads), SAM/BAM (uitlijning), en VCF (varianten). Databanken zoals GenBank en UniProt bevatten referentiegegevens en annotaties die analyses ondersteunen.
Vaardigheden en opleiding
Bio-informatica is interdisciplinair. Een effectieve bio-informaticus heeft meestal kennis van:
- Biologie en moleculaire biologie (concepten zoals genexpressie, mutaties, eiwitstructuur).
- Programmeren en scripting (Python, R, command-line tools).
- Statistiek en data-analyse.
- Werken in Linux/Unix en met versiebeheer (bijv. Git).
- Kennis van cloudplatforms en hoge-prestatiecomputing bij grootschalige datasets.
Praktische voorbeelden
- Identificatie van ziekteverwekkende varianten in menselijk DNA voor genetische diagnostiek.
- Opsporen en volgen van nieuwe virale varianten tijdens een epidemie.
- Ontwikkeling van nieuwe gewasvariëteiten door analyse van genen die resistentie beïnvloeden.
- Ontdekken van kandidaat-geneesmiddelen via virtuele screening en eiwit‑ligand‑modellering.
Uitdagingen en ethische aspecten
Bio-informatica brengt technische en maatschappelijke uitdagingen met zich mee: privacy en beveiliging van genetische data, interpretatie van resultaten (vaak probabilistisch), opslag en beheer van grote datasets, en reproducibility van analyses. Daarnaast vraagt het om transparantie en zorg bij klinische toepassingen: verkeerd geïnterpreteerde computerresultaten kunnen gevolgen hebben voor patiëntenzorg.
Toekomstperspectieven
AI en deep learning veranderen het veld (bijv. structurele voorspelling en patroonherkenning in multi-omics). Single-cell-technologieën, integratie van verschillende soorten omics-data (multi-omics) en real-time surveillancesystemen zullen bio-informatica nog centraler maken in onderzoek, gezondheidszorg en industrie.
Samengevat is bio-informatica een onmisbare schakel geworden tussen experimentele biologie en moderne datawetenschap: met computers en slimme algoritmen maken onderzoekers zinvolle patronen zichtbaar in enorme hoeveelheden biologische data.

Stichting
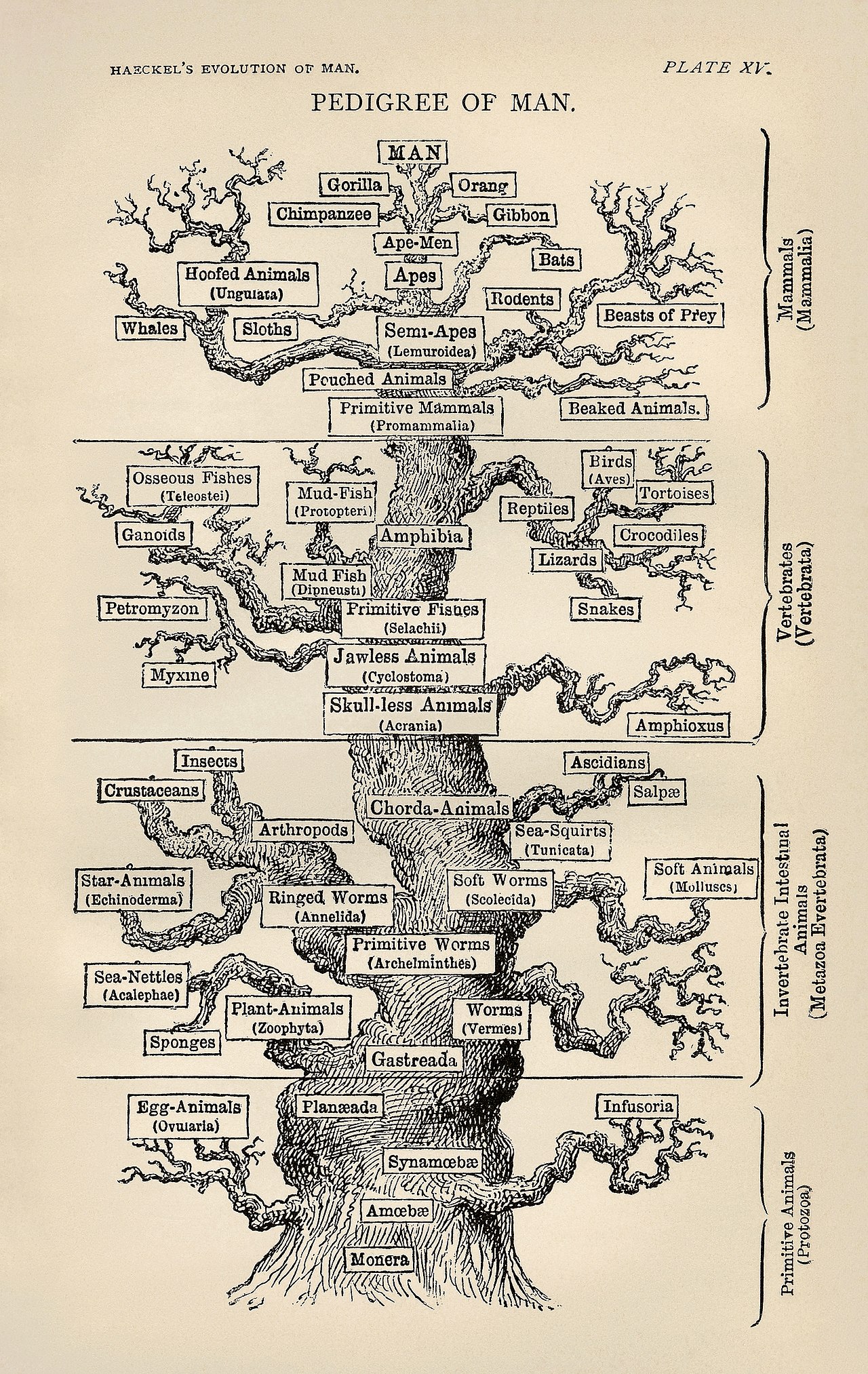
Als soorten levende wezens in de loop der tijd veranderen, verandert het DNA in hun cellen, als gevolg van de evolutie. Als we de informatie van de huidige levende wezens kunnen extraheren en ze met elkaar kunnen vergelijken, kunnen we zien welke levende wezens het meest verwant zijn, net zoals we twee edities van een boek met elkaar kunnen vergelijken: de meest gelijkende kan worden beschouwd als de meest verwante in de tijd. Zo kunnen biologen stambomen of fylogenieën construeren. Door alle bomen aan elkaar te rijgen, kan een grote boom worden gemaakt die alle levende wezens met elkaar verbindt. Bio-informatica is de integratie van wiskundige, statistische en computationele methoden om biologische, biochemische en biofysische gegevens te analyseren.
Het proces
Alles wat een cel maar wil, is opgeslagen in zijn DNA. Wanneer een cel een eiwit wil maken, zoekt hij het juiste stukje DNA, maakt er een kopie van (RNA genaamd), en gebruikt de instructies in de kopie om het eiwit te maken.
Eiwitten zijn de "machinerie" van een cel. Ze kunnen vele functies vervullen, zoals transport, structurele ondersteuning, beweging en metabolisme. Eiwitten worden gemaakt van aminozuren. Er zijn twintig verschillende aminozuren die worden gebruikt om miljoenen verschillende eiwitmoleculen te bouwen.
Het principe van de bio-informatica is dat deze moleculen kunnen worden bestudeerd door computers te gebruiken voor het analyseren van de DNA-, RNA- en aminozuursequenties waaruit zij zijn ontstaan. Omdat er zoveel verschillende moleculen zijn, is de beste manier om te begrijpen hoe het hele systeem werkt de bio-informatica.
Computers in de bio-informatica
Chemici hebben manieren ontwikkeld om de vorm en het gedrag van kleine moleculen te begrijpen, met behulp van wiskundige analyse. Zij zouden computers (of zelfs gewoon potlood en papier) kunnen gebruiken om deze moleculen te bestuderen. Bovendien is het DNA in slechts één cel van een organisme veel te groot om door een mens te worden gelezen, en om het DNA tussen twee (of meer) organismen te vergelijken, of het nu gaat om broer en zus, of om een totaal andere soort, moeten grote hoeveelheden informatie worden vergeleken voor kleine (of grote) verschillen. Computers zijn veel beter geschikt voor dergelijke vergelijkingen, en computerprogrammeurs hebben samen met biologen zeer grote databanken aangelegd om alle DNA-informatie op te slaan die ooit is geleerd. Biochemici proberen tegenwoordig deze vragen te beantwoorden over elke cel in het lichaam:
- Hoe bindt een bepaald eiwit zich aan een ander?
- Welke eiwitten worden opgebouwd uit een specifieke streng DNA?
- Hoe kan DNA worden gebruikt om genetische aandoeningen en ziekten te stoppen?
- Hoe is een cel veranderd door de evolutie?
- Voor welke ziekten is iemand bijzonder kwetsbaar, gezien zijn genen?
Gerelateerde pagina's
Gerelateerde artikelen
Auteur
AlegsaOnline.com Bio-informatica (computationale biologie): wat is het en hoe werkt het? Leandro Alegsa
URL: https://nl.alegsaonline.com/art/11636